

2026 AI Content Brief Template & Structural Guide
TL;DR: This blueprint defines the mandatory engineering standards for content in the "Retrieve-and-Synthesize" era.

TL;DR: This blueprint defines the mandatory engineering standards for content in the “Retrieve-and-Synthesize” era. It mandates semantic chunking, high-density proprietary fact integration, and technical AI-readiness to secure maximum “Share of Model” (SoM) and trigger the high-intent Discovery-to-Search loop across GPT-5.1, Gemini 3, and Claude 4.5.
--------------------------------------------------------------------------------
1. How do we define Core Content Identity and Intent?
Core content identity in 2026 requires precise mapping of “Golden Prompts” to resolve the recursive Discovery-to-Search loop. This process anchors a brand within an LLM’s retrieval set by aligning informational, comparative, or transactional intent with direct, unambiguous solutions that satisfy zero-click requirements while maximizing competitive “Share of Model” (SoM) objectives across generative search interfaces.
Target Conversational Prompts (”Golden Prompts”): The writer must identify 3–5 natural language queries (e.g., “What is the most reliable [Product] for [Specific Use Case]?”) that force the model to evaluate the brand as a primary solution.
Intent Mapping & Solution Focus:
Direct Solution: Define the unambiguous answer the content provides. Content must resolve user intent without requiring an external click.
Intent Category: Explicitly label as Informational, Comparative, or Transactional.
Share of Model (SoM) Classification:
The writer must classify the brand’s current status using the Uri Samet framework: Cyborg (High Awareness/High SoM), AI Pioneer (Low Awareness/High SoM), or High-Street Hero (High Awareness/Low SoM).
Strategic Objective: Define the target “Entity Status” (e.g., Primary Recommendation vs. Technical Ground Truth).
--------------------------------------------------------------------------------
2. How is Structural Engineering applied through Semantic Chunking?
Structural engineering utilizes semantic chunking to organize data into modular, self-contained units of 150–300 words, ensuring optimal ingestion by RAG pipelines. By utilizing Lead-with-Answer (LWA) formatting and question-based H2 headers, content matches the conversational retrieval patterns of models like GPT-5.1 and Gemini 3, facilitating precise, high-confidence machine parsing and passage-level retrieval.
LWA Strict Constraint: The first 40–60 words of every section must directly answer the heading. Fluff, scene-setting, or “SEO introductions” are strictly forbidden to ensure immediate grounding for machine scrapers.
Sectional Chunking Requirements:
Organize content into discrete chunks of 150–300 words (300–500 tokens).
Each chunk must be conceptually complete, allowing RAG systems to retrieve the passage without losing context from parent or sibling sections.
Hierarchical Header Logic:
H2 Headers: Must be phrased as questions to match conversational discovery.
H3 Headers: Must provide granular data, specifications, or specific case examples.
--------------------------------------------------------------------------------
3. What strategies optimize Fact Density and Entity Solidification?
Fact density is optimized by integrating proprietary “Ground Truth” data that provides high Information Gain, a critical factor for the MaxShapley attribution algorithm. By weaving unlinked mentions of experts and partners, we solidify the brand’s position within the semantic Knowledge Layer, increasing machine confidence scores and citation probability by up to 40% through verifiable data.
Proprietary “Statistics & Sources” Table: Mandate a table containing specific numbers, dates, and verifiable facts. Writers must prioritize unique, proprietary research or internal data over public-domain facts to maximize the “Information Gain” score (Source 2.3).
Entity Solidification: Weave in “Named Entities” (people, organizations, locations) to anchor the brand in the global Knowledge Graph. Unlinked brand mentions of partners and competitors must be used to build a “semantic network.”
MaxShapley Attribution Logic: Optimize for “Shapley-value contribution” by providing unique data points that the model cannot synthesize from other sources, ensuring the brand is cited as the definitive source.
--------------------------------------------------------------------------------
4. What are the Narrative Requirements for AEO and GEO?
Narrative requirements for 2026 focus on “Instant Mode” compatibility through bolded TL;DR summaries and structured data formats like comparison tables. These elements are reinforced by authoritative expert attributions secured via C2PA cryptographic signatures, signaling “Radical Transparency” and human verification to counteract the homogeneity of AI-generated content and establish a “Human-Verified” premium in the retrieval set.
The AI “TL;DR”: A 2–3 sentence distillation at the absolute top, optimized for zero-click resolution.
Structured Format Mandates:
Comparison Tables: At least one “X vs. Y” table to capture comparative queries.
Numbered Lists: One procedural list for “How-To” queries to support HowTo Schema extraction.
Authoritative Insight & C2PA: Include an “Authoritative Insight” block with a verified expert quote. This section must include C2PA cryptographic signatures or “Radical Transparncy” protocols to signal human expertise (Source 8.2).
--------------------------------------------------------------------------------
5. What Technical Markup and AI-Readiness Specs are mandatory?
Technical readiness mandates Server-Side Rendering (SSR) to ensure immediate HTML parsing and a comprehensive robots.txt allowlist for specialized crawlers like OAI-SearchBot and PerplexityBot. Implementation of an llms.txt file acts as the definitive “brand identity file,” while detailed Schema.org deployment (FAQPage, HowTo) constrains AI creativity and prevents hallucinations by providing a structured Source of Truth.
Schema.org Deployment Checklist:
FAQPage Schema: Mandatory for conversational query grounding.
HowTo Schema: Required for procedural extractability.
Article & Person Schema: Must connect the author entity to the brand Knowledge Graph.
Robots.txt & LLMS.txt Directives:
Allowlist: Technical teams must explicitly allow OAI-SearchBot, ChatGPT-User, PerplexityBot, and ClaudeBot.
Brand Identity File: Must maintain an llms.txt file in the root directory for agentic discovery.
Indexing Infrastructure: Mandate Server-Side Rendering (SSR). Content must be pre-rendered in plain HTML to avoid retrieval failures caused by JavaScript-heavy client-side rendering.
--------------------------------------------------------------------------------
6. How do we align Sentiment and Agentic Commerce?
Alignment with agentic commerce requires maintaining a high Sentiment Clarity Index and positive Sentiment Velocity to ensure favorability in agent-to-agent negotiations. By adhering to the Universal Commerce Protocol (UCP) and providing a “Fortress of Facts” FAQ, brands protect themselves against “Exclusionary Logic” and the “Warning Effect” during automated discovery and purchasing by AI agents.
Sentiment Velocity & Clarity: Writers must execute a “Sentiment Integrity Check” to ensure “Positive Foundational Favorability.” Monitor the Sentiment Velocity (rate of change) and Sentiment Clarity Index (consistency of social proof) to prevent the AI from triggering guardrails (Source 4.1, 7.2).
Agent-to-Agent Alignment: Present all pricing, availability, and specs in tabular formats compatible with the Universal Commerce Protocol (UCP) for agentic purchasing.
The “Fortress of Facts”: A dedicated FAQ section at the document’s end to serve as “corrective data” against AI hallucinations and misinformation.
--------------------------------------------------------------------------------
7. How are Performance and Visibility measured via GEO KPIs?
Performance is measured through the LCRS framework, tracking consistency and recommendation share across platforms like Claude 4.5 and DeepSeek V3.2. Success is quantified by transitioning from legacy click-based metrics to GEO-first indicators such as Citation Frequency and the Branded Search Proxy, reflecting the brand’s actual influence and salience in the synthesized search landscape.
Table: Legacy KPIs vs. GEO-First KPIs (Source: Uri Samet, 2026)
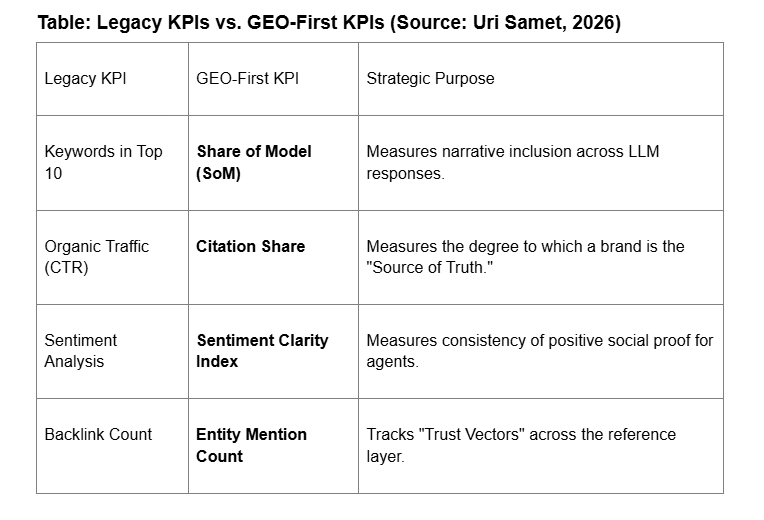
LCRS Measurement: Track Consistency (appearance frequency across prompt variations) and Recommendation Share (competitive frequency against category rivals).
Branded Search Proxy: Measure the increase in direct brand searches triggered by AI mentions (the Discovery-to-Search loop).